This is my first attempt to draw up anything even remotely like what exists today. The later B2 - B4 are a lot better thought out but a great deal of the ideas in those designs started life here.
This design started life in late 1995 after I read about the IBM PPC615 in Byte magazine. There was no diagram present so being interested in chip design I decided to try and figure one out myself. I then read about the Intel/HP design and thought I would try and figure it out instead as it would present more of a challenge. I thought about this for some time but I am an inventor and I devised a number of ideas which were not likely to be in the Intel/HP chip and I eventually decided to try and design my own chip. The first result of this was the B1 for which I wrote a document and drew a diagram, after noticing some flaws I updated this with the improved B1b. This document is an update to the B1b and includes some more fixes and new ideas.
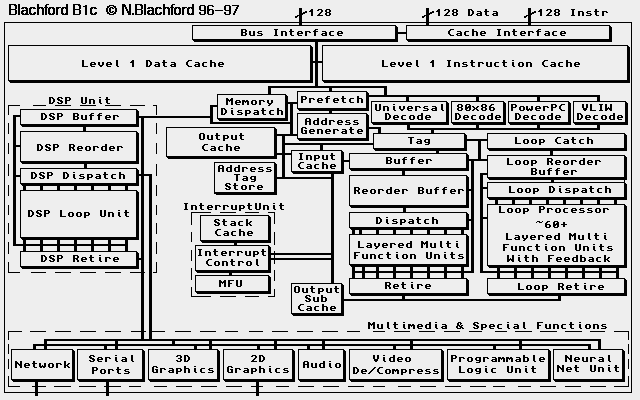
This design follows on from RISC and introduces a new type of Instruction set designed for both compactness and speed but at the same time will remain compatible with previous instruction sets. The instruction units are much larger than usual and there would be many more of them so the transistor count of this chip would be in the tens of millions even before the cache is added. The aim of all this extra logic would be to increase performance to levels previously unseen from a single microprocessor, like some other modern processors special units are included for multimedia data processing and other like functions, unlike other processors these can act as independent units so the main processing is not affected.
B1c Architecture
The B1 is designed as a fast RISC based microprocessor using a number of advanced features to deliver very high performance. If it was built in the way I have envisaged it the performance would be many times that of even the fastest RISC processors currently available. To deliver such speed it would have to use the most advanced chip technology in conjunction with a high performance memory bus.
The speed is attained by using the following features:
Other advanced features are included such as:
Instruction Sets
The processor would use it's own Short Length RISC (SLR) instruction set internally but a number of decoders will enable the processor to decode code from different processors such as 80x86 and PowerPC, these would be hard wired decoders but there would also be a third programmable decoder to allow other instruction sets to be decoded such as Alpha, Sparc or 68K code etc. Another decoder would be used to decompact CLIW code. The Short Length RISC instruction set is a means to save both memory usage and bandwidth allowing the processor to read more instructions in a shorter period of time. The most commonly used instructions would use the smallest instruction numbers while less used instructions would have higher numbers. To save processing time the length of instructions would be fixed in two or three sizes but internally all instructions would be the same size. The Compact Long Word Instruction set (CLIW) uses the numbers given to instructions to compact a large number of instructions into a single long instruction word hundreds of bits long. Because the most common instructions have the lowest numbers, they would compact the most allowing more instructions to be read in a single given cycle. Processors spend a great deal of time reading program instructions from memory but the CLIW reduces this leaving more time to read data.
Code Mode
The Universal decoders would convert different instruction sets into SLR type code for use within the CPU core, however this will have to be done every time a program is run and the extra decoding will affect both memory usage and performance. The way to get round this is to recompile the program for the B1 or perhaps use a binary converter. The B1 however would be able to use its internal decoders to binary convert a program into SLR code, Binary conversion is obviously a complex procedure so some software would be involved but this could be supplied with a system.
CLIW Conversion
After conversion to SLR a CLIW encoder could also be used to compact the program down for minimal memory usage and an optimising compiler could rearrange instructions for maximum speed and memory efficiency. This would not be specific to a particular B1, a B2 would not need a recompilation of B1 code to operate, the main optimisation would be done inside the CPU when a program is run and the CLIW optimiser simply aids this. One of the main pitfalls of existing VLIW technology is that you need to recompile for every generation of processor since the VLIW en/decoders would be specific to the number and type of instruction units in a processor. CLIW ignores the internal instruction units and is used to reduce the physical size of a program and hence the number of memory cycles to read it.
Internal Processing
Most microprocessors are based around a single processing block which will consist of a number of units for processing different types of instructions. Some processors now contain additional processing units for additional operations, examples of these are Sun's VIS and Intel's MMX. The B1 takes this to the extreme by containing a number of dedicated processing units for different operations but also includes a dedicated secondary processor for signal processing (DSP). In addition to these the main processing block is in two distinct parts, one for normal processing and a second section dedicated to processing loops. The primary processing block is superscalar like many processors but this is where the similarity ends. Superscalar processors contain processing units each for a different set of operations and a couple of units for integer processing. The B1 is different in that Multiple Function units (MFUs) are used - every processing unit can perform every operation be they integer, floating point or whatever. The units are also layered, there are a number placed after each other so there is no delay processing results of operations.
The reason all the processing elements are all identical and layered is to allow a greater number of operations to be performed simultaneously, when instructions are reordered the speed of reordering unit is limited because it has to look for both dependant instructions and the type of instructions. The B1 simply ignores the type of instructions since they are not sent to specific units and short sequences of dependant instructions can be sent to the layers. All this adds up to is that more instructions can be dispatched and retired per cycle that any other processor.
The Loop Processor
The second processing block is dedicated to processing loops, processors probably spend most time performing operations inside loops so by increasing their speed the overall processing speed of the microprocessor increases. The design of the loop processor is similar to that of the primary processing block in that Layered MFUs are used but there is additional logic to update loop counters at the same time as an iteration of a loop is occurring. A large number of MFUs would be used so large loop within loops can be calculated, any loop too big for the loop unit would have to be handled by the primary processing block and this would cut performance.
The loop processor would operate by setting up a series of MFUs with instructions and directions of where to send the result, once the instructions are put into place they no longer need to be read, the processor only reads data until the loop is complete. If a loop was dependant on a series of complex operations in a line all of which depended on the result of a previous operation a normal CPU could be crippled by having to wait for the result of each operation, the result of successive iterations of loops could be hundreds of cycles apart. The B1 on the other hand by setting up a pipeline of instructions can deliver the result of an iteration on every cycle provided that the result is not used in the next iteration.
A way of making loops even faster is to run different iterations in parallel, this can only be done where there no dependencies between iterations except the loop counter. When this occurs the loop processor is capable of delivering the result of iterations of complex loops at more than one per cycle - no existing microprocessor is capable of this. The biggest problem in trying to do this is the loop counter, using SLR code this could be identified by the compiler and the loop processor would simply load it into the unit reserved for handling counters. Trying to do this with emulated code however would be more difficult since the processor would not know where the loop was, to resolve this I have devised a unit to find unidentified loops in code. The loop catch unit watches the incoming code for short jumps backward, if it can identify these and find the loop counter it calculates the number of cycles to completion, if this number is greater than the number of cycles necessary to set up the loop counter the loop unit is activated and the program execution transferred to the loop unit.
Zero Register Design
The original design for the B1 didn't use any registers but rather operated on memory directly, the internal buffering and caching would ensure any memory address accessed would be in the cache before it is needed. This would work very nicely but it poses big problems for the CLIW instruction system since addresses would not compact well, the instructions would end up being bigger than other instruction sets. For this reason I added address tagging, this acts as a set of virtual registers, these are not real registers but rather a means of addressing data words without using their full address. When an address is tagged the contents of that address are moved into the processor which holds not just the data but also the address. That piece of data is then referred to by the name of that tag - just like a register. The address tags would also double up as real registers when emulation is used. Both the addresses and the data of an address tag would have a store on the processor to prevent data from being flushed from the output cache and being lost.
By using address tags memory can be operated on directly but without having to specify the full address every time. This fits in well with the CLIW system so that a large number of instructions can be put into a small area. If a program used a small number of tags to do most of it's work and used the more common instructions it might be possible to fit instructions and tag numbers into just 12 bits, this would allow 20 full instructions to be fitted into a 256 bit instruction word - using less than half the memory that a normal RISC processor would use.
Clock Speed
The clock speed of a RISC processor is determined so that most if not all instructions execute in a single cycle, even floating point instructions. This however means that integer instructions which may be much faster operate at the same speed as slower floating point ones and this would be a large disadvantage if a large number of integer instructions were in use as in the case with a great deal of software. To allow for this the CPU would be clocked at a speed where Integer instructions operate in a single cycle and floating point operations take longer. This would allow integer instructions to operate at maximum speed, this would however require very fast logic control on the CPU. In addition to this all units which require more than one cycle to complete their operation would have to be fully pipelined to give a result on every cycle. The clock speed will also have to be slow enough to allow eight instructions to be issued on every cycle, this should not be a problem however as the instruction dependencies can be found at decode (or compile) time and indicated, the reorder unit then simply assigns any instruction to any MFU.
Hardware Multitasking
It is very unlikely that the loop processor would ever be fully utilised by a single program and while it is in use the main processor block will apart from speculative execution of branches, be inactive, To get around this it may be possible to include a hardware multitasking system would allow a second task to run concurrently on the processor, one task would use the Loop processor while the second task runs on the main processor block. This would however present some difficult design problems for the chip designer because it would involve the use of multiple control registers. It would however allow programs to split into different tasks to increase execution speed and emulation to run alongside native programs. On the other hand such a system could prove detrimental to the performance of the processor if the loop processor was performing an operation which required a large throughput of data. The B1 will however be able to do multiple operations simultaneously when the additional function units are in use but these would not interfere in the operation of the main processing blocks to a great extent.
Data Fetching
For a program to execute at maximum speed multiple branch reads would be used to speculatively execute multiple branches in a program, this would allow a calculation to complete and for the next program section to be ready at the outcome of a branch. This would prevent hold-ups which usually occur when a branch is incorrectly predicted. If possible a address will be calculated immediately when a read or write instruction is decoded and this address is sent to the bus controller and the data or instructions read, if it is a read it will be read as soon as any pending reads or writes are complete, Since a 128 bit bus is used the processor can read multiple pieces of data in a single go, these would then be sorted into their correct size in a sorting unit prior to processing.
Processor Flags
Every processor sets flags when a calculation is completed and each processor family has different flags, since the B1 handles different instruction set types there would be a need for a large number of different flag types to be set for each instruction, this would prevent the need for slow software emulation of different types, all these flags would be available to SLR instructions but if they require additional calculations to complete the flags this would only be done when subsequent operations depended on those flags.
Interrupt Handling and Stacks
In a normal processor when an interrupt is called the contents of the processor registers are written onto the system stack and the interrupt handling routine called and executed. The stack is also used when function calls are made to the OS. The B1 operates in a different manner which allows both faster interrupt handling and OS calls. A dedicated Interrupt handler is used when an interrupt is called, this allows the main processor to continue as usual while an interrupt is handled, the interrupt handler would consist of a cut down processing block with it's own Integer units, address generators and registers, If more complex operations were involved the interrupt unit would make a call to the Main block or Loop block, these would hold any competing instructions until the interrupt instruction/s are completed. To increase the speed of interrupt handling the most often called and highest priority calls would be held in a Interrupt cache where they could be called without accessing memory.
When an OS call is made the processors contents would be saved out onto the stack and different instructions then called, to speed up this process there would be a dedicated stack cache. When an OS call is made the data in the CPU is pushed onto the stack cache while the OS call instructions are loaded. The stack cache would consist of several layers to allow a number of calls to be made without having to do a large write to memory, there would however be a point when this would be necessary, there would also have to be spare room to allow the data to be stored in the cache. A dedicated area of the cache could be set aside for commonly called routines.
Digital Signal Processing and Multimedia Units
There are two ways of implementing a DSP in a system, you can use a separate DSP processor, a system which increases system cost, or you can use the CPU to do DSP operations but this can tie up the CPU and prevent it doing other operations. To get around these problems the B1 would implement a dedicated DSP section on the processor, this would operate concurrently with the CPU but would used the CPUs bus system, the DSP could also use additional dedicated lines.
The DSP would work like a Loop processor but with some multimedia instructions handled by dedicated units. The Loop unit would be a cut down version of that used in the main CPU block and would be dedicated to calculations for signal processing like a normal DSP, there would also be an addressing section but nothing like that in the main CPU block. The dedicated Multimedia units would handle 3D graphics calculations, 2D Graphics, Video De/Compression, Audio playback, Serial communications (high speed), Timers and other units. The DSP and other units would be activated by the higher number SLR instructions. It should be noted that while the processor is capable of generating graphics it would not display them, this would be handled by a dedicated chip - this chip will generate enough heat as it is.
Additional Units
It would also be possible to add a couple of units not normally found on CPUs, these are the Neural Net Unit and the Programmable Logic Unit. The Neural Net Unit could be used in programs which require pattern recognition. This would be useful for speech and handwriting recognition. The Programmable Logic Unit would allow complex mathematical formula to be programmed into hardware allowing a large speed boost, such formula may require a great deal of instructions but the PLU allows hardware to be created as and when required. This unit would not be as fast as a dedicated hardware device but would be used to speed up programs significantly. A Library of pre-programmed functions could be supplied with the B1s operating system and the processor could call these in if they are being used frequently.
Output SubCaching
The Output Cache is designed to hold data written out of the processor and this can be read rather than going direct to memory, however some pieces of data may be read only a few instructions after be used, there is already a mechanism for returning results but this will only work when data is used very soon after use, a few instructions later and the data would have been written into the Address Tag store or the output cache, retrieving from these could cause wait states at high clock rates so to avoid this a second output sub cache would be used, which would store data as it comes out of the retirement unit, this data would be checked against any instructions coming into the processor, when a match is found the data is copied into an Input cache where the data is stored until it is read into the input buffer.
Intel/HP VLIW? emulation
The number of MFUs in the original diagram is 8, this is not in any way a pre-set number, if the number can be increased it should be. A large number of MFUs would be very useful when it came to emulating the Intel/HP VLIW architecture, such systems are designed to execute many instructions at once without the use of a Reorder Buffer and this fact could be used to help emulation in the B1b, It may be possible to add an emulation mode where instructions are directly fed into the MFUs bypassing the Reorder Buffer. Another better method would be to decode the instruction words into SLR instructions and execute them in the usual way, this would in fact have an advantage in that this method could execute more instructions per cycle than the Intel/HP chip, their architecture will have a set of instruction units of certain types and a large number of one type of instruction would limit the maximum instructions per cycle, MFUs can cope with any type of instruction so this problem will not occur on the B1b. This method also opens the possibility of the loop processor finding a loop in the code and executing it even faster.
Infinite Addressing
Microprocessors and mainframes alike have all had the same problem occur, that of a limited address space eventually becoming to small for the programs being run. The B1b could use a system which would prevent this problem from ever occurring, that is there would be no fixed maximum address which the processor could address. The processor would probably be fine with 32 bit addressing most of the time and 64 or even 128 bit for more heavy duty applications but there would be an additional mode which allows an address to be longer than an address register. The first word would indicate the number of address words that would be used and the processor would read them. An extension of this would be to have another address word at the end of the address data which indicates if there are any further address words and how many. By using multiple extensions the processor could then handle address lengths which had no fixed limit, this would in effect allow the processor to access an infinite amount of data.
This would be a very complex operation as it involves multiple memory reads just to get the address and an equal number or writes to write it. This would however allow the processor to switch memory banks or to access vast amounts of data (albeit very slowly). Switching banks would open up the possibility of having multiple banks of RAM which could be connected and disconnected while the processor was still running allowing for memory upgrades or repair. This feature may seem of somewhat limited use but it means future designs would also not have to be redesigned from scratch to allow longer address lengths, software would still be compatible many years later.
Back to the Computer Section
![]()