Extreme Parallel Fragment Processor
Copyright (©) Nicholas Blachford 26th October 1998
Extreme Parallel Fragment Processor
Copyright (©) Nicholas Blachford 26th October 1998
The Blachford B4
The following describes firstly the philosophy of the B4, the ideas behind the B4, how it came about and then the B4 itself is described.
The Philosophy of the B4
Before I go into the details I'd like to explain the philosophy of the B4 as this will explain why I've made certain decisions which may not seem to fit with traditional CPU design.
I have been involved in an on-line project to design an "open source" CPU. One of the questions which comes up occasionally - usually from those with CPU design experience - is what is trying to be solved and how many instruction units can be used to solve it. This is a common sense question - there is little point wasting expensive silicon if it's not going to be used much.
This approach is not the one I have subscribed to in the B4. In fact I have purposely used the complete opposite approach. Adding a large number of instruction units as well as raising the possibility of new instructions, both of these will take up huge numbers of transistors to implement.
It may be quite correct that on "average" code only 1 instruction unit can be utilised 100% of the time and even going beyond 3 can be seen as excessive. I however question the concept of average code. There are some tasks which will take all the parallelism that is thrown at them, there will also be programs which may use 2 instructions on average but have sections which can use a great deal more. There are some tasks which are full of mathematical operations for which there may be no direct support in the CPU.
All processors with the possible exception of Merced will used the "standard" approach - i.e. a limited number of function units. On programs which can use a greater number of function units Merced (or McKinley) will probably be the leader unless a competitor can challenge this with raw clock speed. The aim of the B4 is to not only run at a high clock rate but also to allow high levels of parallel operation for both integer and floating point operations. In programs where a very high level of parallelism can be used - where even Merced runs out of steam - the B4 will deliver it. When these high levels of parallelism are not required the B4 will act more like a multiprocessor running multiple programs or threads, like 4 Merceds.
This may be a very expensive approach to building a CPU but within the next 10 years transistor budgets will be approaching 1 billion transistors per chip and such an approach will become feasible. Rather than simply adding ever greater amounts of Cache RAM, I propose the B4 as a CPU which uses some of these gigantic budgets to provide a processor which can not only performs well on average code but can deliver very high performance with code which requires a very high level of single thread parallelism. A feat which no other single CPU will be capable of.
If new mathematical instructions are added code size can be reduced while large performance increases are observed. This is another feat the B4 will perform which competing processors will not be capable of. Although mathematical instructions may be of limited use to some users they will be very useful in some areas - including advertising!
How the B4 came about
This B4 project began after I read about the sort of processing going on in things like hardware 3D graphics accelerators where there are a great many operations going on at once. I wondered what would happen if there was a general-purpose processor which could achieve that sort of parallelism as standard - how an "extreme parallel" processor would operate and perform. I've also been reading about things like Motorola's Altivec and similar techniques and wondered about an extreme parallel CPU where SIMD type instructions were standard.
I know that the average execution rate in general purpose CPUs is fairly low, around 2 instructions per cycle. But I also know that from even simple pieces of code written by myself there is a much greater level of parallelism to be found if you are prepared to look for it. I write Audio-processing software in which the most important parts are the processing functions, these generally consist of loops where there may not be a great deal of parallelism due to dependencies. However if the iterations of the loop were split up and parts of different iterations executed in parallel the amount of parallelism increases dramatically.
So I set about thinking about a design which would have an unprecedented amount of execution units. A CPU which even at modest clock rates would outperform even the fastest CPUs by a large margin given the right tasks. A CPU which did not need 3D graphics or MPEG acceleration as these algorithms could be performed at sufficient speed in software alone.
My first idea was to have a 128 bit register file with 128 entries and 32 MFU execution units. An MFU is an idea I thought up some time ago for the B1, they contains both Integer and Floating point calculation units but this definition would be extended to include SIMD instructions as well. Altivec can compare 16 bytes in a single cycle, the B4 will (in theory) compare 512 bytes per cycle - at 2GHz that's 1 terabyte per second! I have a fairly simple loop which even on the fastest CPU would still take in the region of 5-10 cycles to complete a single iteration. My hypothetical CPU would complete an iteration on every cycle providing memory could keep up.
32 Execution units complicates things a great deal as they would involve a large number of busses to transport data to and from the register file and this could seriously complicate things. The idea of an extreme parallel processor may be good but that's no use if it's impossible to build it!
I had however already found a solution to this problem in an existing hypothetical design called the B3. It has a large number of execution units but they are split across 4 "Fragment" Processors. If I modified the B3 design so the register files were larger and I increased the number of execution units to 8 per Fragment processor I could achieve my goal of 32 MFUs.
The B3 was based on the idea of Fragment processing where a program is split into small chunks, I had devised a way to execute a large number of instructions per cycle but hadn't really thought it out that much. By combining the ideas in the B3 with extreme parallel processing you get the benefits of both approaches - a CPU capable of a large number of executions per cycle on those applications that can use them and the ability to run multiple threads in parallel when they can't.
Thus, the B4 was born.
This should not needlessly complicate software or compilers but inevitably there will be some complication. If I used the idea of an implicitly parallel instruction set from yet another hypothetical design called the F1n there will be no need for out of order instruction hardware and it should be possible for the B4 to have a high clock rate as well as extreme parallel execution. The idea of an implicit parallel instruction set allows parallelism to be found by the compiler but it does not tie the compiler to the number of execution units. Rather than stating what is parallel, the compiler merle reorganises code and indicates what is dependent. The CPU can then assume all instructions can be executed in parallel and issues them only holding dependant instructions.
There seem to be three approaches to CPUs at the moment:
Unlike anyone else the B4 uses all of the above. Unlike any of the above approaches the fragment processors can be combined to run a single program at much higher speed - much higher than any other CPU.
The Blachford B4
Extreme Parallel Fragment Processor
The following is a modified version of the original document I wrote to describe the B3, The design of the B4 is very close so I haven't rewritten it but the B3 is referred to a few times.
Although below I say implementation I don't mean this in the usual sense. The B4 is a hypothetical architecture and as such is really only a vehicle for my ideas on microprocessor architecture. This design is not set in stone, rather it could be considered at freshly poured wet cement. If someone was to go and try and actually build one it would probably end up looking very different from what I describe here with more ideas being added and some being removed. For example asynchronous operation of the Fragment Processors is probably necessary for high speed but the split clock they use may actually hinder things.
Fragments I had the idea of splitting program into Fragments some time ago but it took me a long time to fully understand exactly how they could be used for any useful purpose. The B3 design was my first attempt at trying to figure out how a Fragment based CPU would operate, this B4 design is a more advanced version.
A Fragment processor operates in a significantly different manner from conventional CPUs. All program code is split up at compilation time into a series of Fragments consisting of one or more processor instructions. When executed the Fragment and the data it requires is sent to a processing unit then executed. Once complete the data is moved out and another Fragment is moved in, the new Fragment may or may not be related to the previous one. It neither knows nor cares, all it has to do is complete it's own processing then exit.
This is the idea behind Fragment processing. It doesn't sound very spectacular but as I shall explain below it allows you to do things which a conventional processor would not allow.
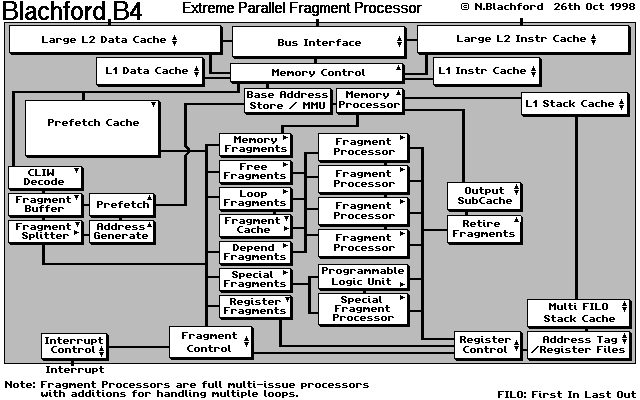
The Hypothetical B4 implementation The diagram is to show the basic ideas and layout.
In the B4 I have taken ideas from the previous designs and with somewhat more knowledge about how CPUs operate I have designed the B4 around the idea of Fragment processing. Although it contains some of the same ideas the B4 is a completely different design from the B1c or the B2, It is however a very close relation of the B3 and pinches some ideas from the F1n. For details of these other designs see: www.hearit.demon.co.uk/computer.html
The process starts with data being read into the CLIW decoder. CLIW stands for Compact Long Instruction Word and is a means by which instructions could be packed into a single long data word. The purpose of this is to reduce the average length of instructions and the bus bandwidth required to load them. This would free up the bus for moving more data. A single CLIW word may include many instructions but these could be single or multiple Fragments.
Once the Fragments are decoded to their full length they are written into a buffer. Each Fragment requires data and it is at this point the addresses are generated and this data is prefetched.
The Fragments then move into the Fragment Splitter where they are divided into categories and sent to buffers to await execution. There are 6 types of Fragment in the B4:
1) Memory Fragments These are instruction sequences which operate directly on memory. These can consist of block data moves, simple assigns and possibly some simple calculations. A dedicated Memory Processor is used to generate the addresses and / or data required by these instructions.
2) Free Fragments These are Fragments which can be executed out of sequence. If a branch has two possible outcomes and these do not depend on data processed in the previous fragments both can be executed simultaneously by different Fragment Processors. Simple loops can be issued to the Free Fragments unit where they shall be sent for execution in a single Fragment Processor.
3) Loop Fragments These are Fragments which contain loops or are loops which are spread over a number of Fragments. The latter will most likely happen in loops which contain other loops. The Loop Fragments can issue a single iteration of a loop as Fragment providing there are no inter-loop dependencies. This means that a single loop can use all 4 Fragment processors without having to be specifically modified to do so.
Another trick the Loops Fragments unit can do is to take over all 4 Fragment Processors to allow the handling of large multi-Fragment loops. In order to do this the loop must be split into 4 and a part executed on each Fragment Processor in turn. The Loop in effect has to be pipelined and for this purpose there are input/output ports on the fragment processors so data can trickle through the fragment processors.
On loops which require more than 4 fragments a fragment cache is used to store the fragments which are not in use. This allows a pipelined type operation to happen but where only certain parts of the pipeline can be used at any one time.
4) Depend Fragments These are Fragments which specifically depend on data in a previous Fragment. These cannot be issued for execution until the previous Fragment is completed. This does not cover Fragments which contain jumps as although the next Fragment/s depend on this result they may not require data generated by it.
5) Special Fragments Most modern day processors now come with some form of acceleration for multimedia and other instructions. The B4 would be no different and have a dedicated processor for this purpose. The use of SIMD instructions in the Fragment processors would reduce the need for this unit somewhat but there may be some instructions which might still be required. In addition to the special Fragment processor a Programmable Logic Unit would be present where custom circuits can be configured and used on the fly.
One possibility for The Special Fragment processor is to handle Floating Point divide instructions, the latency with these instructions is so long that they would cause potential problems in the main Fragment Processors.
6) Register Fragments These are Fragments which operate on the Address Tag/Register Files. These can be loads, saves and moves. Moves will be used a great deal in a Fragment processor as different Fragments will require data spread across the Register File and the Fragment Processors will not have access to them all. It should be noted here however that while this would have been a potential problem on the B3 this is not so on the B4. The B3 Fragment processors would have had considerably less registers (probably 16) whereas the B4 will have 64 register per Fragment Processor.
B4 Registers and Address Tags The above paragraph may seem a little strange as all processors can usually access the full register set. One exception to this is register windows but even there if the window is changed all registers can be accessed. This is definitely NOT the case in the B4.
The B4 has a number of Address Tag/ Register files. As well as a 128 bit data register the address of the data is stored in an Address Tag. This allows data to be written back to memory or moved between locations without having to specify memory addresses as the address in the Address Tag would store this.
These Register Files are organised so only a subset of the file is available to Fragments. When a Fragment is issued for execution to a Fragment Processor a set of 64 registers in that Processor is filled up with the data that Fragment works on. While this may seem like a limitation it is not given that a Fragment is only a small snippet of code which will not contain a large number of instructions. Each Fragment Processor in the B4 is to run at a high clock rate and a relatively small register set will ensure register lookups will be fast.
The Register Files in the B3 will contain 256 entries but since no more then 64 registers will be read out at once for transfer it will not be possible to address individual registers. When transfers are required between register sets the Register Fragments will be read out and transferred in the Register Control unit then written back to one of the Register Files.
There are not just 256 Registers however. There are 8 separate Register Files, each of which is assigned to a program or thread. One is permanently assigned to the Operating System kernel. When the kernel is about to swap threads one of the suspended Register Files is switched out to the Stack Cache and the register file then filled with data from the next thread, this will all happen in the background while other threads are still running. Once this is complete one of the running threads is suspended while the new thread is started. This should allow threads to be started and stopped with an effective context switch latency of zero.
The Register Files are 128 bit wide with a further 128 bit Address Tags. These Registers can be accessed as 8bits 16bits etc up to 128 bits at a time, fixed or floating point values can be stored. There is no need for address registers as all Registers have Address Tags and it would be possible to manipulate these.
Clock Speed The Fragment Processors will run asynchronously from the rest of the B4 using a high speed split clock. The split clock will allow only the fastest operations to operate in a single clock cycle. A logical operation may operate in a single cycle but an integer multiply (and possibly add) will not.
This means that logical type operations shall be executed very fast but many operations will also speed up as a result of this clocking. If an operation takes say 0.6 of a cycle to complete normally and the split clock was for example 10 times higher it would now operate in 6 split clock cycles as opposed to 10 if it used the lower clock, (it is highly unlikely the split clock would be this high).
A disadvantage of this system is that complex operations which normally take a large number of cycles will now be even higher. An option here would be to split such operations into very small Fragments and allow these to be processed alongside a separate Fragment. This would complicate things but not too much if the long operation was not duplicated in the second Fragment.
Another disadvantage is that many operations will now take several cycles to complete meaning they would have to be pipelined and this could seriously complicate their circuitry. Consequently the exact speed of the split clock would have to be looked at so it does not over complicate things. It may be possible to increase the clock speed perhaps a small amount and need only to pipeline only a few operations. The clock speed increase however has to be at least a factor of 2 otherwise some operations will actually slow down. The split clock should thus be considered as an optional part of the B4 design!
The Fragment Processors Fragment Processors do all the data processing in the B4. They perform the integer and floating point instructions, contain their own 64 entry register sets, and have facilities for multiple loop counters. The Fragment Processors are almost full RISC processors in their own right but they do not directly read or write data to or from memory and don't have any control over overall program flow.
Unlike many RISC processors there is no hardware for finding parallelism within programs, this will be handled by the compiler (al la Merced). The Parallelism however is strictly limited to no more than 8 calculation issues per cycle but the Fragment Processor can do reads and writes to it's register files while these are being executed. Splitting the Register file & instructions units up will simplify this process a great deal.
The Fragment Processors will perform processing using MFUs, another idea borrowed from one of my previous designs. An MFU is a Multi-Function-Unit, It is a single unit which can handle all operations, integer or floating point. The original idea behind them was to simplify out of order instruction logic, in the case of Fragment Processors however there is no such logic but the MFUs will still make life easier for both the compiler and the instruction scheduler. It also allows the number of MFUs to be changed without destroying software compatibility.
A conventional out of order CPU has to look at the type of instruction and then figure out if the relevant unit is free, if not the instruction is held. An MFU based processor only looks at which instruction can be issued, sees if any MFU is free and if so issues it. The type of instruction is irrelevant as every MFU can take every instruction.
The only exception to this is where a long non-pipelined multi cycle instruction has been issued and this "locks" an MFU. One possibility would be to make such instructions only available as Special Fragments, this would have issues itself but would at least not tie up or complicate other MFUs.
MFUs probably won't make much of a difference to number of instructions issued per cycle but the simpler logic should allow the clock speed to be higher. Having said that the sheer size of multiple MFUs might effect the clock speed.
SIMD-MFUs In a difference from the B3 the MFUs in the B4 are SIMD based. This means they can handle 16*8bit, 8*16bit, 4*32bit, 2*64bit or 1*128 bit instructions per cycle with similar figures for Floating point instructions. This means an individual Fragment Processor can in theory issue 128 8bit operations per cycle. This alone is much higher then any other CPU but combined with 3 other Fragment Processors doing the same means the B4 will be able to have some pretty potent processing power. 2D and 3D Graphics will benefit greatly from this level of parallelism.
Additional Instructions Many workstations are used for engineering and academic areas where they are put to use performing complicated mathematical operations. Adding specific hardware for these types of operations will increase both the size and complexity of the MFUs but will have a significant effect on performance in these areas.
Fragment Retirement Once a fragment is complete it's results cannot always immediately be written back to memory. If the fragment has been issued out of order it has to be retired in the correct order. If a pair of Fragments have been issued speculatively the outcome of the choosing Fragment has to be checked to ensure the correct Fragment is chosen. If data from one Fragment is required by the next it has to be sent back or held in the Fragment processor while the next loads.
Writing to Memory Once Fragments are retired their data can then be written to memory, the full register set, or both. The Base Address Store generates the Full 128 bit address. To save on address size space programs could operate with 64, 32 bit or 16 bit addressable ranges. This saves on instruction address space but also saves the CPU from sending gigantic addresses all over itself. All addresses will however need to be recalculated to their full 128bits and this is handled by the Base Address store. The MMU then generates the final physical address.
Cache Sizes and Types The Cache for a B3 will be a pretty complex affair as it will require multiple caches to allow for multi threading/processing. Currently this would cause a CPU to bloat to ludicrous proportions but if someone was to actually build a B4 it wouldn't be ready until the time 0.10 micron technology was beginning to appear. Consequently the size of multiple L1 caches would not by then be such a big deal, neither for that fact would multiple SIMD-MFUs. I fully expect that the logic alone of a B4 would dwarf even the largest of today's CPUs. It would require hundreds of millions of transistors to manufacture in full. If there is a candidate for the first 1 billion transistor CPU the B4 would be a good bet!
And Last but not least...
Performance
The B4 is a multi-threaded multi-issue out of order CPU. In essence it can run several programs at once and each of these programs can issue multiple instructions per cycle.
I have tried to keep things simple - there is no complex out of order circuitry in the Fragment Processors and the use of MFUs simplifies the compilers ability to schedule by allowing instructions of any type. In addition to this the Fragment processors will run asynchronously from the rest of the B4 and from each other. In short an individual Fragment Processors should be able to run at a high clock rate and issue a large number of instructions per cycle.
Fast Fragment Processors will be no use if the CPU cannot issue Fragments at a high enough rate to keep them sustained. Fragments can be issued out of order but this will be a rudimentary capability. The CPU will not go looking for the absolute maximum Fragments it can issue but if it can issue 3 at a time it will do so. Fragments require data to operate on and this will be gathered from memory or the register file while the Fragments are being held prior to execution. Streams of data to and from memory would of course also be permitted.
Context switching or thread swapping can both be hidden in the background by reading Fragments and issuing other threads for execution. There is no reason for the CPU to suddenly stop when a cache miss occurs as this to can be covered by executing a Fragment from a different thread.
Both the Fragment Processors and the CPU infrastructure should be capable of running at a high rate due to a lack of needless complexity.
So, providing the memory system can keep data supplied to the B4 core it should execute programs at a very fast rate indeed. If four threads can issue just one instruction per cycle this is 4 instructions per cycle - this low rate is equal to greater than the peak rate of many RISC processors. Even if the B4 has a relatively moderate clock rate in average operation it should be able to run rings around everything except multi core CPUs or multiprocessors.
The B4 should be especially good on Floating Point applications - how many other CPUs will be able to perform 128 32bit Floating Point operations per cycle?
Given that the B4 has 4 Fragment Processors you would expect it to be as fast as a multiprocessor system and perhaps even faster... A multiprocessor system requires communication between CPUs to keep data constant, in addition the CPUs will fight each other for Data in memory.
The B4 is however not a multiprocessor and does not require the communication overhead in either hardware or software, additionally it cannot fight itself for memory access. Requests for data will be held until the bus is ready, a process which will take less time in a single processor than on 4 spread over a motherboard.
---
Additional ideas
High bandwidth memory. Using 16 RDRAM channels should provide in order of 25 GBytes per second of memory although even this would not even nearly keep the B4 fed when it is operating at near maximum speed. However given most programs will rarely if ever get maximum performance out of the B4 this shouldn't too much of a problem.
Multi bus system. In order to maximise memory performance I propose a triple bus system for the B4. The first is a large wide bus based on RDRAM or other high bandwidth memory, this is a memory ONLY bus. Second would be an input/output, bus this could be based on a similar bus structure as RDRAM (small number of tracks at a very high speed) and would connect with PCI slots, Hard Discs etc... Thirdly would be another bus system similar to the I/O but this time dedicated to graphics. The graphics CPU would have it's own frame buffer but would also be capable of reading direct from main memory via the B4. A fourth bus system could be used for communication in multiprocessor systems.
Graphics operations as CPU instructions When a line has to be drawn it generally involves a program calling an operating system routine which then calls a driver which then calls the graphics hardware and finally the line is drawn. This is probably a simplification so as you see even simple operations can involve a number of steps. In order to simplify these steps I propose placing some graphics operations into the B4 as instructions. By doing this the above steps are no longer necessary as the B4 will directly perform the graphics operations. This should provide a significant performance boost for all graphics operations.
This would involve adding an additional function unit to the B4 (not the MFUs) and might require another type of Fragment.
Back to the computer section